
محاسبات در جایی که دادهها قرار گرفتهاند
عنوان اصلی مقاله: Computing Where Data Resides
تاریخ انتشار و نویسنده: March 29th, 2021 – By: Ann Steffora Mutschler
![]() وبسایت منتشر کننده: Semiconductor Engineering
وبسایت منتشر کننده: Semiconductor Engineering
لینک اصلی مقاله
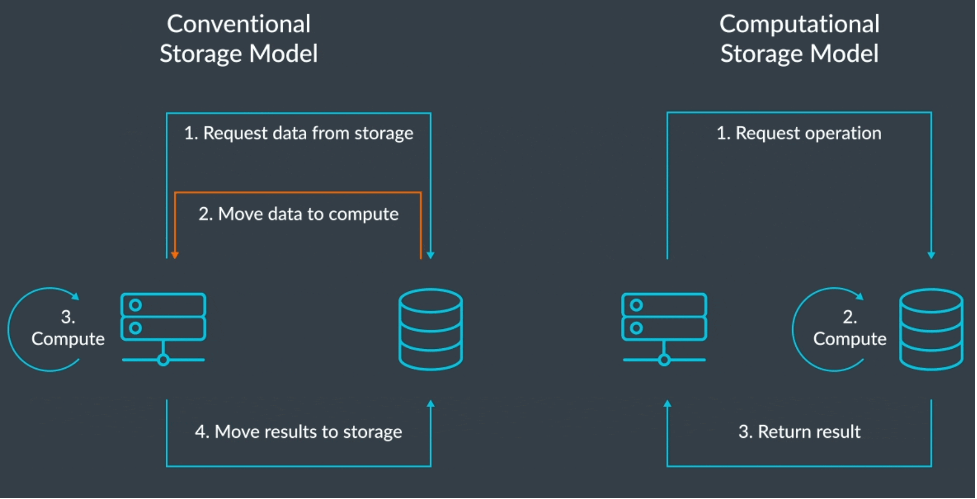
رویکرد ذخیرهسازی محاسباتی (رایانشی)، محدودیتهای «توان» و «دیرکرد» را جابجا میکند.
در حالی که معماران سامانهها، با چالشهای همزمانی چون افزایش تاثیر جابجایی مقادیر زیاد دادهها میان پردازندهها، حافظههای سلسلهمراتبی (Hierarchical memory) و ذخیرهسازها بر عملکرد، مصرف انرژی و میزان دیرکرد (Latency) دستوپنجه نرم میکنند، کشش جدیدی برای استفاده از ذخیرهسازی محاسباتی یا ذخیرهسازی رایانشی (Computational storage) شروع به پدیدار شدن کردهاست.
طبق گفتهی آیدیسی (IDC, International Data Corporation)، حجم دادههای جهانی از ۴۵ زِتابایت در سال ۲۰۱۹ تا ۱۷۵ زِتابایت در سال ۲۰۲۵ رشد خواهد کرد. اما اساساً این دادهها بیفایده خواهند بود، مگر آنکه تجزیه و تحلیل شده و یا حداقل مقداری محاسبات بر روی آنها انجام شود؛ این در حالی است که انتقال این دادهها به پردازندههای مرکزی (CPU) بیشتر از خود محاسبات، انرژی صرف میکند. رویکردهایی مانند ذخیرهسازی محاسباتی سعی در کاهش این مشکلات دارند.
مقایسههای متعدّدی میان ارزش نفت و داده (Data) انجام شدهاست. کارتک سِرینیواسان (Kartik Srinivasan)، مدیر بازاریابی گروه مراکز داده شرکت زیلینکس (Xilinx) میگوید: «به طور منطقی نفت و داده هر دو بیفایده هستند، مگر آنکه روی آنها کاری انجام دهید. نمیتوانید نفت خام را در اتومبیلتان بریزید؛ برای اینکه قابل استفاده شود باید بر روی آن فرآوری انجام دهید. این حتی در رابطه با دادهها بیشتر چالش برانگیز است؛ چرا که میزان دیرکردی که در دسترسی به دادهها در طول فرایند تجزیه و تحلیل ایجاد میکنید، فوقالعاده حیاتی است. هنگامی که یک کارگزار سهام، اطلاعاتی دریافت میکند که میگوید: «این معامله توسط موتور تحلیل بازار به شما پیشنهاد میشود.» اگر پنج دقیقه دیرتر به دستش برسد، دیگر فایدهای ندارد. بنابراین اگر تجزیه و تحلیل بر روی دادهها با میزان دیرکرد مناسب انجام نشود، ارزش داده از بین خواهد رفت.»
انواع و اقسام بسترهای اشتراکگذاری و پخش آنلاین (Streaming) دادهها باعث افزایش میزان تولید، مبادله و به اشتراکگذاری دادهها شدهاند. طبق مشاهدات اسکات دورانت (Scott Durrant)، مدیر بازاریابی بخش ابری دیزاینور آیپی (DesignWare IP) شرکت سیناپسیس (Synopsys)، همهگیری حاضر [کرونا] تقاضا را برای ظرفیتهای بالاتر مراکز داده، سرعت شبکه، ظرفیتهای ذخیرهسازی و عملکرد بالاتر تشدید کرده است. «این امر با وجود کووید (Covid) به شکل نمایی افزایش یافته و انتظار میرود تغییراتی که در نحوهی کار کردن، نحوهی یادگیری، نحوهی تعامل، و نحوهی سرگرمی ما ایجاد شدهاند، دائمی باقی بمانند.»
در نتیجه، اکنون طراحان «سامانه روی یک تراشه (SoC, System on a Chip)» که دستگاههایی برای کاربردهای با سرعت بالا و دیرکرد پایین تولید میکنند، شروع به بررسی معماریهای جایگزین از جمله ذخیرهسازهای محاسباتی کردهاند.
دورانت میگوید: «همزمان با این موضوع که میبینیم سامانههای کنترلی بیشتری برخط (Online) میشوند، اهمیت حیاتی میزان دیرکرد پایین نیز افزایش مییابد. در کنار این، یکی دیگر از موارد مورد توجه در مراکز داده، بهینهسازی در بهکارگیری انرژی است. در حال حاضر یک حرکت بزرگ به سمت صفر کردن خالص رد پای کربنی در مراکز داده آغاز شده است که در واقع یک چالش بزرگ است؛ چرا که امروز مراکز داده مصرفکنندگان عظیم نیرو هستند؛ بنابراین از این پس دیگر تمام عناصر مرکز داده نقش خود را حول این چالش ایفا خواهند کرد. هر جا که صحبت از بهینهسازی مصرف نیرو شود، مراکز داده مسیر خود را به سمت آن چه به صورت سنّتی معماری دستگاههای همراه (Mobile) بوده است، تغییر میدهند. سالهاست که دستگاههای همراه در تلاش هستند با به حداقلرساندن مصرف نیرو و خاموش کردن آن قطعاتی از دستگاه که در یک زمان مشخص استفاده نمیشوند، عمر باتری خود را به حداکثر ممکن برسانند. امروز پیادهسازیهای مشابهی در مراکز داده مشاهده میکنیم تا بهرهوری نیرو به حداکثر رسانده شود. همچنین، معماریهای جدیدی نیز برای پردازندهها معرفی شدهاند که به طور معمول در دستگاههای همراه استفاده میشدند. به عنوان نمونه، اکنون پردازندههای آرم (Arm) زیرساختهای مراکز داده را هدف قرار دادهاند؛ ضمن آنکه پردازندههای آرم و ریسک-وی (RISC-V) به اندازهی کافی آن آزادی دارند و باز هستند که بتوان آنها را برای یک بار کاری (Workload) خاص بهینهسازی کرد.»
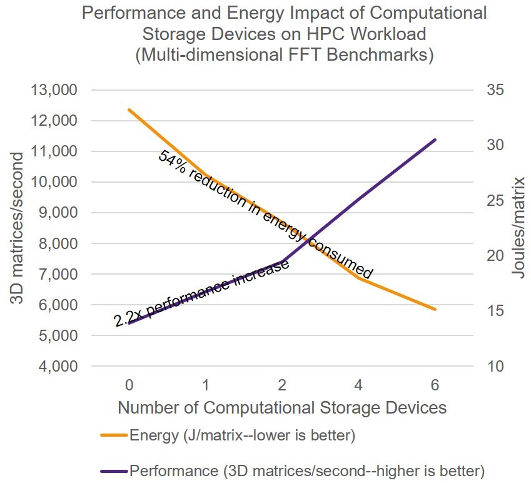
تصویر ۱: تأثیر ذخیرهسازی محاسباتی بر مصرف انرژی. منبع: سینوپسیس (Synopsys)، بیست و یکمین کنفرانس آیتریپلای (IEEE) با موضوع اِچپیسیسی (HPCC)، اوت ۲۰۱۹
این همان جایی است که ذخیرهسازی محاسباتی، به کار میآید. سِرینیواسان میگوید: «ایدهی انجام رایانش مستقیماً بر روی دادهها از ابتدا مطرح بوده است. اما با تحول دیجیتال (Digital transformation)، اکنون سختافزارهایی با قیمت معقول برای انجام تجزیه و تحلیل و نرمافزارهایی با چارچوبهایی که اجازه دهند آن تجزیه و تحلیل انجام شود، وجود دارند. اکنون این اجزاء به نحو مطلوبی در حال قرار گرفتن در کنار یکدیگر هستند؛ دادهها به شکل دیجیتال هستند، سختافزارهای مقرون به صرفه موجود هستند، و چارچوبهای نرمافزاری برای اجرا در دسترس هستند.»
البته، این دشوارتر از آن است که به نظر میرسد. استیون وو (Steven Woo)، همکار و مخترع برجسته در شرکت رَمبس (Rambus) میگوید: «دیسکها و دیسکهای متعددی مملو از دادهها وجود خواهند داشت، و ممکن است شما تنها به یک یا دو تکه از آنها نیاز داشته باشید، اما همهی آنها باید جستجو شوند. روش مرسوم برای انجام این کار این است که همه چیز داخل دیسکها را بردارید، آنها را به یک سیپییو (CPU) منتقل کنید، و سپس سیپییو همه چیز را جستجو کند و ۹۹٬۹۹۹٪ آنها را دور بیندازد. در واقع مقدار زیادی از کارهایی که انجام میدهد هَدر میرود. ممکن است به طریقی دیگر آرایهای از دیسکها وجود داشته باشد و سامانه به نحوی تنظیم شده باشد که تمام دادهها را به صورت موازی منتقل کند تا فرایند سریعتر شود؛ اما باز در نهایت، همچنان یک سیپییو وجود دارد که در جستجوی دادهها بوده و خود یک گلوگاه میشود.»
وو میگوید: «این همان جایی است که ذخیرهسازی محاسباتی واقعاً میدرخشد. اگر هر یک از دیسکها در خود کمی هوشمندی داشته باشند، چه رخ میدهد؟ آنگاه این امکان وجود خواهد داشت که به همهی دیسکها بگویید: «به طور موازی جستجو کنید؛ یعنی بروید و هر یک از شما تمام اطلاعات خود را مرور (Scan) کنید، فقط آنچه را که با این درخواست خاص من مطابقت دارد، به من برگردانید.» جالب اینجاست که من پهنای باند و انرژی را برای دادههایی که هرگز استفاده نخواهم کرد هَدر نمیدهم. همه چیز به صورت محلی (Local) باقی میماند و من فقط چیزهایی را مشاهده میکنم که با معیارهای جستجوی من مطابقت دارند.»
کاربردهای گسترده
کشش جدیدی برای استفاده از ذخیرهسازی محاسباتی در لایهی لبه (Edge) شروع به پدیدار شدن کردهاست؛ لایهی لبه، یک سلسلهمراتب نامرتب از منابع محاسباتی است که گسترهای از دستگاههای انتهایی (End devices) تا انواع مختلف سرورهای نصبشده را چه در محل (on-premise) و چه بیرون محل (off-premise) شامل میشود. هدف در همهی آنها، در صورت امکان، انجام هرچه بیشتر محاسبات در نزدیکی منبع و محدود کردن فاصلهای است که آن داده نیاز به پیمودن دارد.
نیل وِردمولر (Neil Werdmuller)، مدیر راهحلهای ذخیرهسازی در شرکت آرم میگوید: «آنچه که امروز اتفاق میافتد این است که دادهها در هر صورت منتقل میشوند، حتی اگر در خود لایهی لبه تولید شده باشند؛ چه تصاویر دوربینهای نظارتی باشند و چه پلاکهای خواندهشدهی خودروها. به طور معمول، تمام یک جریان داده به جایی دورتر برای سرور اصلی ارسال شده و سپس در آنجا پردازش میشود. تنها چیزی که ممکن است هر از چندگاهی از تمام آن جریانهای سنگین دادهها استخراج شود، مثلاً یک شماره پلاک ساده است که این واقعاً دیوانگی است. اگر بتوانید پردازش را در خود لبه انجام دهید، آنگاه فقط همان تصویر یا مقدار استخراجشدهی مورد نیاز را به آن جایی که لازم باشد ارسال میکنید؛ این بسیار منطقیتر خواهد بود.»
تصویر۲: ذخیرهسازی محاسباتی در مقابل ذخیرهسازی سنّتی. منبع: آرم
مثال دیگر میتواند در تنظیمات مخابراتی 5G باشد، زمانی که ذخیرهسازی محاسباتی در پای برجهای سلولی (Cell towers) پیادهسازی میشود. طبق گفتهی وِردمولر «اگر وسیلهی نقلیهای از محدودهی آن سلول خاص عبور کند، در صورتی میتوان به آن خودرو خدمات نقشه با کیفیت بالا (HD) ارائه داد که کاشیهای تصویری که نیاز هستند، در همان محلی که به آنها نیاز است ذخیره شده باشند؛ این در مقابل آن وضعیتی است که تمام وسایل نقلیهای که از محدودهی آن سلول عبور میکنند، مجبور باشند مکرّراً یک کاشی تصویری یکسان را هر بار از نقطهای مرکزی بارگیری (Download) نمایند. تمام آن انتقالهای رفت و برگشتی گران هستند، انرژی مصرف میکنند و موجب افزایش در «دیرکرد» میشوند؛ زیرا که غالباً با جابجایی دادهها در این روش، «دیرکرد» نیز موضوعیت پیدا میکند.»
همچنین، پردازش دادهها در لبه دارای مزایایی از دست حریم خصوصی و امنیتی نیز هست.
اما همهی دادهها را نمیتوان در لایهی لبه جمعآوری و پردازش کرد، در اَبر (Cloud) نیز فرصت بزرگی برای استفاده از ذخیرهسازی محاسباتی وجود دارد.
وِردمولر میگوید: «مدیریت همهی این دادهها واقعاً چالش برانگیز بوده و بارهای کاری به شدت در حال انفجار هستند. مدیریت تمام حجمکارها در سرور و اجبار به انتقال دادهها به آن سرور پیچیده است؛ مصرف نیرو را افزایش میدهد، به دیرکرد میافزاید. بنابراین اگر شما ذخیرهسازی را در اختیار داشته باشید که دادههای بهخصوصی بر روی آن ذخیره شدهاند، میتوانید بار کاری بهخصوصی نیز در اختیار داشته باشید که بر روی آن دادهها اعمال میکنید. به عنوان نمونه، اگر میخواهید از یادگیری ماشینی (Machine learning) با توانایی تشخیص چهره بر روی تعداد زیادی عکس بهره بگیرید، اگر بدانید که آن عکسها کجا بر روی درایوها ذخیره شدهاند، آنگاه اجرای آن بر روی دادههای حقیقی بسیار منطقیتر به نظر میرسد؛ شما بار کاری کمتری را به شکل متمرکز مدیریت کردهاید و قادر میشوید بارهای کاری را توزیع نمایید.»
همهی اینها به دلیل انرژی و زمانی که برای جابجایی دادهها صرف میشوند و افزایش حجم دادههایی که باید خیلی سریع پردازش شوند، برای شرکتها جذابیت پیدا کردهاند. وو میگوید: «اگر انرژی و زمان زیادی صرف نمیشد، مشکلی نیز وجود نداشت. وقتی شما این توانایی را دارید که اطلاعات دارای موضوعیت را تنها برای رایانش مرکزی منتقل نمایید، شاید قادر باشید که مقدار کمی محاسبات ساده در فضای ذخیرهسازی انجام دهید. حال اگر شما آن توانایی را داشته باشید که تنها مقادیر کمتری از دادههای بسیار معنیدار را برای سیپییو ارسال کنید، آنگاه سیپییو تلاش خواهد کرد و تا زمانی که قادر باشد خواهد توانست آن دادهها را پیش خود نگه دارد؛ سیپییو آن زمانی قادر است فنون یادگیری ماشینی را اجرا کند که دادهها را پیش خود نگه داشتهباشد و تلاش کند آنها را جابجا نکند. چیزی که در تمام اینها به آن امیدوار هستید اتفاق بیفتد این است که جابجایی دادهها در دیسکها را به حداقل برسانید. آنگاه، وقتی که چیزی معنیدارتر یافتید، میتوانید آن را برای پردازندهی مرکزی ارسال کنید، لذا دیگر پهنای باند هَدر نمیرود، چون تنها چیزهای معنیدار را ارسال کردهاید. آنگاه پردازنده آن را تا آنجا که ممکن باشد نگه داشته و سعی میکند آن را جابجا نکند. همهی اینها برای به حداقل رساندن جابجایی دادهها طراحی شدهاند.»
تکامل از اِساِسدی (SSD) به سیاِسدی (CSD)
از منظر طراحی، مسیر حرکت از درایو حالت جامد (SSD, Solid state drive) به دستگاه ذخیرهساز محاسباتی (CSD, Computational storage device) یک مسیر تکاملی است.
بِن وایتهد (Ben Whitehead)، مدیر محصول راهحلهای بخش تقلیدکننده (Emulation) در زیمنس ایدیاِی (Siemens EDA) میگوید: «تا حدود سال ۲۰۱۹، ما مشغول حل یکی از بزرگترین مشکلات «تقلیدکنندهها» بودیم، آنجایی که کاربران در تلاش بودند تا بتوانند در داخل اِساِسدیها (SSDs) کار کنند؛ یعنی بتوانند عملکرد – به ویژه آیوپس (IOPS) (ورودی / خروجی در هر ثانیه) – و پهنای باند و میزان دیرکرد را اندازهگیری کنند. مشکل عظیم دیگر روشهای تصدیق (Verification) در آن زمان، میزان دیرکرد در آنها بود، چرا که خیلی دقیق نبودند. شاید شما قادر بودید یک راه حل با عملکرد صحیح پیدا کنید، و در نظر اول با خود بگویید «وای، چه عالی»، ولی به محظ آن که شما نتیجه آخرین فاز طراحی (Tape-out) را بر میداشتید و وارد آزمایشگاه میشدید، متوجه میشدید که عملکرد آن به مرتبه بزرگی از پیشبینیهای شما فاصله دارد. شرمآور بود که چهقدر بد عمل میکرد. کار میکرد، اما واقعاً ما در مرحلهی قبل از ساخت (Pre-silicon) قادر به اندازهگیری دقیق کارکرد نبودیم. این تازه دشواری کار با تنها یک اِساِسدی است. اما یک محصول جنبی جالب توجه که حاصل همهی آن کارها بر روی اِساِسدیها بود، این بود که اِساِسدیها شروع به جایدادن پردازندههای متعدّد در درون خود کردند، پردازندههای بلادرنگ (Real-time). من بر روی طرحهای هشت ریزپردازندهی نسبتاً بزرگ در حال طراحی کار کردم و دیدم که چگونه آنها در یک سامانهی دیجیتالی که ذخیرهساز شما در آن خاموش است، دادهها را خیلی سریع تحویل داده و سپس به نوعی بیکار (idle) میمانند. پردازندهها بیشتر اوقات بیکار مینشینند و وقتی که به آنها نیاز شد، به یک باره واقعاً مورد نیاز میشوند. مانند یک خلبان جت جنگنده که چهار ساعت کسالتآور منتظر است و به دنبال آن ناگهان ۱۵ ثانیهی وحشتآور تجربه میکند. این کاری است که درایوها انجام میدهند. آنها مینشینند، تنها در انتظار اینکه دادهها را به شکل انفجاری عقب و جلو کنند. با وجود تمام آن قدرت پردازشی که در آنها است، این منطقی بود که بخواهیم کار بیشتری با آنها انجام شود.»
سیاِسدیها (CSD) به مشکل جابجایی دادهها پاسخ میدهند. وایتهد میگوید: «حافظههای نهان لایهی دو، اِلتو کَش (L2 Cache) دائماً با درخواستهای داده برای CPU روی مادربُرد (Motherboard)، بمبباران میشوند. وقتی پردازنده آن همه زمان صرف جابجایی دادهها به جلو و عقب میکند، این سؤال ایجاد میشود که، «ما داریم اینجا چه کار میکنیم؟» و نیز این درک را ایجاد میکند که بیشتر آن پردازش میتواند در جای دیگری انجام شود. آنجاست که واقعاً برای استفاده از سیاِسدی کشش ایجاد میشود، اینکه بتوانیم بخشی از آن توان پردازشی بر روی خود دستگاههای ذخیرهساز را استفاده کنیم.»
دیگران نیز موافق هستند؛ کورت شولر (Kurt Shuler)، معاون بازاریابی شرکت آرتریس آیپی (Arteris IP)، میگوید: «ده سال پیش درایوهای حالت جامد (SSDs) جدید بودند. در واقع هنوز چیزی به عنوان اِساِسدی صنعتی یا سازمانی (Enterprise) وجود نداشت. بلکه ریزکنترلگرهای کوچکی بودند که بر روی درایوهای سخت از نوع صفحهای نصب میشدند. این وضعیتی بود که نیمههادیها در آن زمان در آن قرار داشتند. از آن موقع، خیلی چیزها تغییر کرده است. تعداد زیادی شرکتهای نوپا روی کنترلگرهای پیشرفته اِساِسدی کار کردهاند که مشکل اولیهی آنها مرتبط با این واقعیت بود که حافظههای فلش (NAND flash) در حین کار بخشی از خود را از کار میاندازند، بنابراین شما باید همیشه سلامت سلولها را پایش کنید. هر زمان که بفهمید تعدادی سلول خراب شدهاند، باید جدایشان کرده و اعلام کنید که دیگر هیچ چیز در آنجا ذخیره نشود. اگر یک درایو ۱ ترابایتی اِساِسدی بخرید، در واقع بیش از ۱ ترابایت فضا دارد، چرا که در زمان عملیات، خودش را تا حد مرگ خسته میکند. در رابطه با کنترلگرهای اِساِسدی، این چالش اولیه بود. اما اکنون شرکتهای تولیدکنندهی دیسکهای ذخیرهساز ادغامهای زیادی را تجربه کردهاند. اگر به آنچه در ذخیرهسازی محاسباتی رخ میدهد نگاهی بیندازید، مشاهده میکنید که ما الان مشتریانی داریم که در مراکز دادهی خود از حافظهها و کنترلگرهای اِساِسدی که برای یک کاربری خاص مانند نظارت تصویری متمرکز شدهاند، استفاده میکنند. بنابراین در عمل آن محاسباتی که با یک موضوع خاص سر و کار دارند، داخل همان کنترلگرها انجام میشوند؛ این کاملاً جدید است. در این محاسبات، مواردی مانند تجزیه و تحلیلهای الگوریتمی سنّتی اگر/آنگاه (if/then) را مشاهده میکنید. سپس، برخی از اینها موتورهای هوش مصنوعی (AI) آموزشدیده هستند. اکنون، مسیر حرکت تمام اِساِسدیها و کنترلگرهای اِساِسدی صنعتی به همین سمت است.»
این امر در حال تغییر شکل فضای رقابتی است، به ویژه که شرکتهای ذخیرهسازی سنتیای مانند وِسترن دیجیتال (Western Digital) شروع به طراحی شتابدهندههای سخت افزاری متعلق به خود کردهاند.
درک ذخیرهسازی محاسباتی
این مفهوم از نقطه نظر فنی نسبتاً ساده است. مارک گرینبرگ (Marc Greenberg)، مدیر گروه بازاریابی محصولات گروه مالکیتهای معنوی در شرکت کَدنس (Cadence) میگوید: «یک تابع جمعکننده یا شمارندهی ساده را در یک نرمافزار در نظر بگیرید، x = x + 1. اگر x چیزی باشد که ما زیاد از آن استفاده میکنیم، احتمالاً به هر ترتیب در یک حافظهی نهان (Cache) یا حافظهی چرکنویس (Scratchpad) بر روی قالب پردازندهی مرکزی (CPU die) ذخیره خواهد شد. اما بیایید فرض کنیم که ما تعداد زیادی از این شمارندهها داریم و یا خیلی اوقات از برخی از آنها استفاده نمیکنیم؛ آنگاه، برخی از آنها در حافظهی خارجی مانند دیرَم (DRAM) ذخیره میشوند. وقتی زمان آن فرا برسد که آن عملیات x = x + 1 را انجام دهیم، باید یک صفحه را در حافظه فعال کنیم، x را از دیرَم بخوانیم، x را به یک پردازنده منتقل نماییم، 1 را به آن اضافه کنیم و سپس دوباره آن را در دیرَم بنویسیم. بسته به اینکه این فرایند چه مقدار طول بکشد، ممکن است لازم شود از قبل، صفحه را در حافظه شارژ کنیم و سپس زمانی که آماده نوشتن شدیم، دوباره آن صفحه را فعال کنیم. همهی اینها انرژی صرف میکنند، هم برای اینکه دادهها بین دیرَم و سیپییو و دوباره دیرَم جابجا شوند و هم به خاطر اینکه یک صفحه در دیرَم فعال شده و خود جریان میکشد و انرژی مصرف میکند.»
طبق نظر گرینبرگ اگر داخل دستگاه حافظه یک عنصر منطق ساده وجود داشت، یک تراکنش میتوانست به این شکل ارسال شود: «عدد 1 را به محتوای حافظه در آدرس x اضافه کن و نتیجه را برگردان.» با این کار، انرژی مورد نیاز برای انتقال اطلاعات بین رابطها به نصف کاهش مییابد، مدت زمان مورد نیاز برای فعال نگاه داشتن آن صفحه در حافظه کاهش مییابد و بار از روی سیپییو برداشته میشود.
از همین مثال ساده میتواند یک میلیون حالت منشعب شود. او میگوید: «حالا، آیا باید این قابلیت به هر x = x + y نیز تعمیم داده شود؟ اگر سرریز (Overflow) کرد چه؟ آیا باید امکان تفریق نیز داشته باشد؟ ضرب چهطور؟ در مورد سایر توابع پایه واحد محاسبه و منطق (ALU) مانند مقایسه (Compare)، جابجایی (Shift)، توابع دودویی (Boolean) چه میکنید؟ در نهایت میبینید که به یک سیپییوی ثانویه در حافظه تبدیل شدهاست که شاید لزوماً چیز بدی هم نباشد، اما امروزه با توجه به وجود مبنای فکری «همهمنظوره ساختن»، چنین چیزی اتفاق نمیافتد. حداقل در کوتاه مدت اینطور به نظر میرسد که این مسیر با پردازندههای دارای عملکرد ویژهی داخل حافظه آغاز شود. به عنوان مثال، شرکتهایی هستند که بعضاً با ساخت دستگاههای سفارشی حافظه که توابع پردازش ریاضی هوش مصنوعی را در داخل خود دارند، برخی توابع هدایتشدهی هوش مصنوعی را در همان حافظه انجام میدهند.»
مشکلاتی که باید برطرف شوند
دارکو توموسیلوویچ (Darko Tomusilovic)، سرپرست بخش تصدیق در شرکت ویتول (Vtool)، میگوید: «برای اینکه این مفهوم کار کند، باید داخل حافظه، قدرت منطق اضافه شود و شما باید تعدادی کنترلگر را به عنوان بخشی از بلوک حافظه، بخشی از منطق حافظه اضافه کنید. این با فلسفهی جداسازی پردازنده از حافظه تناقض دارد. حالا شما یک قطعهی منطقی را در داخل خود حافظه قرار دادهاید و حالا هنگامی که میخواهید کنترلگرهای حافظه را در فرایند تولید تصدیق کنید، باید در نظر داشته باشید که این دیگر فقط یک کنترلگر حافظهی احمق و گنگ نیست. حالا میتواند یک کارهایی هم انجام دهد. این به طور کامل مفهوم تصدیق را به هم میریزد. به عنوان نمونه، قبلاً مجبور بودیم ابتدا زیرسامانهی حافظه را تست کنیم، و سپس آن زیرسامانهی حافظه را در محیط کامل تراشه ادغام نماییم، لذا این موضوع که تستهای نرمافزاری باید تنها به عنوان بخشی از تست کامل تراشه اجرا شوند، کم و بیش یک روش متداول بود. اما در حال حاضر اینها بسیار بیشتر در هم تنیده شدهاند. از همین منظر است که میبینیم تقاضای زیادی برای به خدمت گرفتن مهندسین متخصّصی ایجاد شده است که تمرکز اصلی آنها بر روی تصدیق کنترلگرهای حافظه است، حالا دیگر این تقریباً یک حرفهی کاملا مستقل شدهاست. به عنوان یک شرکت خدماتدهنده، تقاضای زیادی را به طور خاص برای این حرفه میبینیم.»
اندی هاینیگ (Andy Heinig)، رئیس دپارتمان محصولات الکترونیکی کارآمد در فرانهوفر آیاِساِس (Fraunhofer IIS)، خاطرنشان میکند: «در عین حال، برای چنین رویکردهایی در همهی سطوح، دچار فقدان استاندارد هستیم. برنامهنویسان میخواهند که در چارچوبها (Frameworks) برنامهنویسی کنند؛ به این معنی که در سطح بالا بر اساس کتابخانهها (Libraries) (مانند تِنسورفلو (Tensorflow) برای برنامهنویسی هوش مصنوعی) برنامهنویسی کنند. نرمافزارها نیز در سطوح انتزاعی بسیار مختلفی برنامهنویسی میشوند، مانند برنامهنویسی راهاندازها (Drivers) در سطح پایین، کتابخانهها در سطح اول، کتابخانههای در سطح بالاتر بر اساس قبلیها، برنامهنویسی نرمافزارهای کاربردی (Applications). شاید این امکان وجود داشته باشد که محاسبات داخل حافظهای را در سطح راهاندازها کپسوله کرد، اما تصور ما این است که امکان شناسایی تمام پتانسیلهای این رویکرد از این طریق مقدور نباشد. تنها در صورتی بهرهگیری از پتانسیل کامل امکانپذیر خواهد بود که شما به این مکانیزم از تمام سطوح برنامهنویسی دسترسی داشته باشید، چرا که در آن صورت الگوریتم نرمافزار کاربردی قادر خواهد بود به طور مستقیم از محاسبات شتابدادهشده بر روی دادهها استفاده نماید. اما، دسترسی از تمام سطوح برنامهنویسی به آن، به این معنی است که وجود استانداردها در همهی سطوح برنامهنویسی، برای دستیابی به سازگاری میان کتابخانههای مختلف یک الزام است. برای تحقّق این نوع برنامهنویسی در سطح چارچوب، ابتدا این موضوع باید در تعداد زیادی سطوح پایینتر محقّق شود. اگر برای هر معماری لازم باشد کار از نو انجام شود، وقتگیر و نیروبر خواهد بود. بنابراین باید برای هر سطح از جمله سطح سختافزار، نرمافزار و راهانداز استاندارد آن ایجاد شود.»
در بسیاری از پیادهسازیهای سیاِسدی (CSD)، به جای استفاده از یک پردازندهی بلادرنگ در داخل درایو، از یک پردازندهی کاربردی (Applications processor) بهره گرفته میشود. آقای وایتهد از زیمنس ایدیاِی (Siemens EDA) خاطرنشان میکند: «پردازندههای کاربردی نیازمندی و روش بهکارگیری کاملاً متفاوتی نسبت به پردازندههای بلادرنگ دارند. آنها کاملاً متفاوت هستند. برخی ارائهدهندگان پردازنده از جمله شرکت آرم، در پاسخ به وجود این اختلافها، به طور اختصاصی پردازندههایی با چندین هسته برای ذخیرهسازی محاسباتی تولید کردهاند که در آنها هر دو عنصر پردازندههای بلادرنگ و پردازندههای کاربردی ترکیب شدهاند، و در نتیجه میتوان پردازش را در هر دو وضعیت انجام داد.»
طبق گفته وایتهد، بیشتر مهندسینی که در خصوص پردازندههای بلادرنگ، اِساِسدیها و کنترلگرها تجربه دارند، به نحوهی کارکرد این نوع سیپییوها نیز آشنا هستند. «همراه با یک پردازندهی آرم، شما یک سفتافزار (Firmware) دارید که روی آن اجرا میشود، خواندنها و نوشتنها و زبالهروبیها و تمام آن چیزهایی را که بر روی یک اِساِسدی لازم دارید، انجام میدهد؛ اما اکنون شما یک پشتهی کامل لینوکس (Linux) نیز در داخل دستگاه تحت آزمون (DUT) خود اضافه کردهاید، و این پیامدهایی در طراحی و نیز در تصدیق به همراه خواهد داشت؛ چرا که شما الان دیگر یک سامانهی کاملاً برپاشده در درایو خود دارید. در نظر یک کامپیوتر میآید، و این به معنی چیزهای مختلفی است. هنوز باید در ظاهر از منظر میزبان (Host) خود شبیه یک اِساِسدی باشد که بتوانید آن را در داخلش نصب کنید. هنوز میگوید که «من یک درایو هستم، و میتوانم تمام نیازهای ذخیرهسازی شما را پاسخ دهم.» اما اگر این سامانه آگاه باشد که یک سامانهی لینوکس نیز در داخل خود دارد، میتوانید به داخل آن سامانه اِساِساِچ (SSH) بزنید، و بعد دقیقاً داخل آن درایو مشابه یک سرور بیسر (Headless) به نظر خواهد رسید.»
هر زمان که این موضوع را مد نظر قرار دهیم که بزرگترین کشمکش ما با مقولهی «عملکرد» و «دیرکرد» است، مجموعهی کاملاً متفاوتی از استانداردهای تصدیق مطرح میشوند.
او میگوید: «اکنون شما یک پردازندهی کاربردی را داخل درایو خود اضافه کردهاید. چگونه آن را اندازهگیری میکنید؟ اگر در حال کار باشد و شما لازم داشته باشید آن را در وضعیت بلادرنگ، راهاندازی مجدد (Reboot) نمایید، چه اتفاقی رخ میدهد؟ حالا شما دیگر واقعاً متغیرهای دیرکرد خود را به هم ریختهاید و ارقام کاملاً کج و معوج دریافت خواهید کرد. شما باید پیشبینی این وضعیتها را نیز بکنید.»
او در عنوانکردن این موضوع تنها نیست. وِردمولر از آرم میگوید: «اساساً، اگر به سراغ ایدهی لینوکس بروید، دیگر تفاوتی به غیر از میزان ممکن محاسبات وجود نخواهد داشت. اگر به عنوان نمونه به یک کارت شبکهی هوشمند آرم نگاه کنید، یا یک سرور مبتنی بر آرم، یا یک سرور اینتل زِئون (Intel Xeon)، چون بارهای کاری بسیار زیادی دارد و در حال مدیریت خیلی از امور است، معمولاً محاسبات بسیار سنگینی در آن انجام میشود. این میتواند برای برخی از بارهای کاری رویکرد مناسبی باشد. البته در مواردی دیگر، واقعاً مزیتهایی در انجام محاسبات توزیعشده به شکل محلّی وجود دارند؛ وقتی به جای آنکه همهی کارها برای یک محاسبهی واقعاً سنگین جابجا شوند که مقدار زیادی نیرو صرف خواهد شد، هر درایو تکههای کوچکی از آن کار را انجام میدهد. باید توجه داشت که یک محدودیت مشخص برای مصرف نیرو وجود دارد؛ معمولاً حداکثر تا ۲۵ وات برای هر شکاف پیسیآیای (PCIe) وجود دارد که بیش از ۲۰ وات آن برای تآمین نیرو به حافظهی فلش (NAND) و رَم (RAM) در دستگاه مصرف میشود. بنابراین شما تنها ۵ وات برای تمام کارهای دیگر در اختیار دارید. به نظر کم میآید، اما همچنان با این سطح از محاسبات نیز میتوانید کارهای زیادی انجام دهید.»
نتیجهگیری
با انتقال بیشتر محاسبات به حافظهها، سایر قسمتهای معماری محاسبات نیز در حال تغییر هستند. سِرینیواسان از زیلینکس (Xilinx) میگوید: «قبلاً، تعریف قدیمی ما از سرور این بود که یک پردازندهی مرکزی در داخلش هست که مسؤولیت تمام اتفاقات را بر عهده دارد. تمام پردازشهای کاربردی، تمام دادهها توسط سیپییو انجام میشوند و بقیهی تجهیزات جانبی تقریباً تنها مسؤول ورود دادهها به پردازنده، ذخیرهسازی آنها یا اجازه به حافظه چرکنویس برای دسترسی به دادهها به هر دلیل محاسباتی میانی، هستند.»
او میگوید: «اکنون، همینطور که این صنعت به آرامی شروع به تکامل میکند، یک تقسیم مسؤولیت نیز ایجاد شدهاست. از اَبَرمقیاسهای بزرگ گرفته تا سازمانهای کوچکتر، همهی آنها این واقعیت را پذیرفتهاند که تمام بارهای کاری به یک شکل ایجاد نمیشوند. شما میخواهید قادر باشید از سیپییوها در کار مناسب، از جیپییوها (GPUs) در محل صحیح، و از اِفپیجیاِیها (FPGAs) برای آن کاری که توانایی انجامش را دارند استفاده کنید. به همین منظور است که مفاهیم ذخیرهسازی محاسباتی، در سطح درایو، پردازنده یا آرایه اعمال خواهند شد.»
منتشر شده در وبسایت Semiconductor Engineering
۲۹ مارس ۲۰۲۱ – توسط: آن استِفورا موچلر
برگردان توسط حامد معینفر
در شرکت مهندسین فناور پندار آریا – پنداریا
