عنوان اصلی مقاله: How AI Will Transform Project Management
تاریخ انتشار و نویسنده: by Antonio Nieto-Rodriguez and Ricardo Viana Vargas, February 02, 2023
 وبسایت منتشر کننده: Harvard Business Review
وبسایت منتشر کننده: Harvard Business Review
لینک اصلی مقاله
خلاصه: امروزه، تنها ۳۵درصد از پروژهها با موفقیت به سرانجام میرسند. یکی از دلایل این نرخ ناامیدکننده در سرنوشت پروژهها، سطح پایین بلوغ فناوریهای در دسترس برای مدیریت پروژهها است. امّا اکنون این وضعیت در حال تغییر است. محقّقان، شرکتهای نوپا و سازمانهای نوآور، شروع به بهرهگیری از هوش مصنوعی (AI)، یادگیری ماشینی (ML) و سایر فناوریهای پیشرفته در مدیریت پروژهها کردهاند و این حوزه تا سال ۲۰۳۰ دستخوش تغییرات اساسی خواهدشد. به زودی این دست از فناوریها انتخاب و اولویتبندی پروژهها را بهبود خواهند بخشید، بر پیشرفت آنها نظارت خواهند کرد، سرعت تولید گزارشات را افزایش خواهند داد و موجب تسهیل در آزمونهای تحویل خواهند شد. مدیران پروژه، با بهرهگیری دستیاران مجازی در پروژهها، بیشتر از آنکه نقش خود را بر کارهای اداری و دستی متمرکز سازند، به مربّیگری اعضای تیم پروژه و مدیریت انتظارات ذینفعان خواهند پرداخت. نویسندگان این مقاله میخواهند نشان دهند که چگونه سازمانهایی که تمایل دارند از مزایای فناوریهای نوین در مدیریت پروژهها بهره ببرند، باید از همین امروز کار خود را با جمعآوری و پاکسازی دادههای موجود در پروژهها آغاز نمایند.

تصوّر نمایید در آیندهای نزدیک، مدیر عامل یک شرکت بزرگ ارائهدهندهی خدمات مخابراتی چگونه از یک برنامهی کاربردی بر روی گوشی هوشمند خود برای بررسی آخرین وضعیت «هفت ابتکار راهبردی» که در سازمان او در حال اجراست، استفاده خواهد کرد. تنها با چند اشاره، او از وضعیت هر پروژه و اینکه چند درصد از مزایای مورد انتظار در آن پروژه محقّق شدهاند مطلع میشود. در هر لحظه، منشورهای پروژه (Project Charters) و شاخصهای کلیدی عملکرد (KPI) در دسترس او هستند، همینطور سطح روحیهی هر یک از اعضای تیم پروژه و میزان کلّی رضایت ذینفعان کلیدی.
او به عمق بیشتری از جزئیات «اقدام ابتکاری برای بازسازی نام تجاری سازمان» دسترسی دارد. چند ماه پیشتر، یک رقیب بزرگ، یک خط تجاری جدید اصطلاحاً «سبز» راهاندازی کردهبود که باعث شد شرکت او نیز سرعت پیادهسازی راهحلهای مبتنی بر قابلیتهای پایداری (Sustainability) را افزایش دهد. بر اساس مؤلّفههای انتخابشده در زمان آغاز این «اقدام ابتکاری» توسط مدیر پروژه و تیم پروژه، بسیاری از خودتنظیمگرهای مبتنی بر هوش مصنوعی از قبل اعمال شدهاند. این برنامهی کاربردی، مدیر عامل را از هر تغییری که نیاز به توجّه داشتهباشد – و همچنین مخاطرات بالقوهی ناشی از آن تغییرات – آگاه میسازد و تصمیماتی را که او باید اتخاذ نماید اولویتبندی کرده و راهحلهای بالقوه را نیز برای هر کدام از آن موضوعات پیشنهاد میکند.
مدیر عامل قبل از هر انتخاب یا اقدامی، ابتدا با مدیر پروژه که اکنون بیشتر وقت خود را صرف مربّیگری و پشتیبانی از تیمش کردهاست، ارتباط خود با سهامداران کلیدی را به صورت منظّم حفظ نموده و یک فرهنگ با عملکرد بالا را پرورش دادهاست، تماس میگیرد. چند هفته پیش، پروژه دچار اندکی تأخیر شدهبود و برنامهی کاربردی روی گوشی هوشمند مدیر عامل به او توصیه کردهبود که تیم باید از شیوههای چابک (Agile) برای سرعتبخشیدن به یک رشتهی خاص از فعالیتها در پروژه بهره بگیرد.
در طول جلسه، آنها راهحلهای احتمالی را شبیهسازی کرده و در خصوص مسیر پیشِ رو به توافق میرسند. برنامهی پروژه به طور خودکار بهروز شده و پیامهایی ارسال میشوند تا اعضای مرتبط در تیم و ذینفعان پروژه را از تغییرات و پیشبینی نتایج مورد انتظار ناشی از آن تغییرات مطّلع نماید.
به لطف فناوریها و روشهای جدید کاری، یک پروژهی راهبردی که احتمال داشت از کنترل خارج شود – یا شاید حتّی منجر به شکست شود – اکنون دوباره در مسیر صحیح منتج به موفقیت و حصول نتایج مورد انتظار قرار گرفتهاست.
چنانچه به زمان حال بازگردیم، مدیریت پروژهها همواره به همین راحتیها پیش نمیرود، اما این آیندهای است که آن را برای شما ترسیم کردیم و احتمالاً کوتاهتر از یک دههی دیگر به حقیقت خواهد پیوست. برای اینکه زودتر به آنجا برسیم، سازمانها و نوآوران باید از هماکنون بر روی فناوریهای مدیریت پروژه سرمایهگذاری نمایند.
مدیریت پروژهها در زمان حال و مسیر پیشِ روی آن
هر ساله حدود ۴۸ تریلیون دلار در پروژههای مختلف سرمایهگذاری میشود. با این حال، طبق آمار گروه اِستَندیش (Standish)، تنها ۳۵ درصد از پروژهها موفّق ارزیابی میشوند. در ۶۵ درصد دیگر پروژهها میزان هَدررفت منابع و مزایای تحقّقنیافته مایهی شگفتی است.
سالهاست که در تحقیقات و انتشارات خود، نوسازی روشهای مدیریت پروژه را ترویج کردهایم. متوجّه شدهایم که یکی از دلایلی که موجب نرخ موفقیت بسیار ضعیف در پروژهها است، سطح پایین بلوغ فناوریهای موجود برای مدیریت آنها است. اکثر سازمانها و رهبران پروژه همچنان از «صفحات گسترده» (Spreadsheets)، اسلایدها و سایر برنامههایی استفاده میکنند که در چند دههی گذشته پیشرفت چندانی نداشتهاند. شاید این ابزارها برای ارزیابی موفقیت پروژه با اندازهگیری نتایج قابل تحویل (Deliverables) و موعدهای مقرّر (Deadlines) کافی باشند، اما این ابزارها در محیطی که پروژهها و اقدامات ابتکاری همواره در حال تطبیق با شرایط جدید هستند و کسبوکار به طور مداوم تغییر میکند، ناکافی هستند. پیشرفتهایی در برنامههای مدیریت سبد (پورتفوی) پروژهها حاصل شدهاست، اما هنوز قابلیت برنامهریزی برای ایجاد همکاریهای بین تیمی، خودکارسازی و بهرهگیری از ویژگیهای «هوشمند» وجود ندارد.
اگر در مدیریت پروژهها هوش مصنوعی و سایر نوآوریهای مبتنی بر فناوری قادر باشند نسبت موفقیت در آنها را تنها تا ۲۵ درصد بهبود بخشند، ارزش و مزایای بهکارگیری این ابزارها برای سازمانها، جوامع و افراد معادل تریلیونها دلار خواهد بود. تمام هستههای فناوری که در داستان بالا شرح داده شدند همین حالا نیز آمادهی بهرهبرداری هستند؛ اکنون تنها سؤال این است که با چه سرعتی میتوان این ابزارها را به طور مؤثّری در مدیریت پروژهها اعمال کرد.
تحقیقات گارتنر (Gartner) نشان میدهند که تغییرات به سرعت در راه هستند و پیشبینی میکنند که تا سال ۲۰۳۰، ۸۰ درصد از وظایف مدیران پروژه توسط هوش مصنوعی که از کلاندادهها (Big Data)، یادگیری ماشینی (ML) و پردازش زبان طبیعی (NLP) پشتیبانی میکند، اجرا خواهند شد. تعدادی از محقّقان، مانند پُل بودریو (Paul Boudreau) در کتاب خود، استفاده از ابزارهای هوش مصنوعی در مدیریت پروژه، و تعداد فزایندهای از شرکتهای نوپا، مجموعهای از الگوریتمها (خوارزمیها!) را برای بهکارگیری هوش مصنوعی و یادگیری ماشینی در دنیای مدیریت پروژه توسعه دادهاند. زمانی که این نسل بعدی از ابزارها به طور گسترده مورد استفاده قرار گیرند، تغییرات اساسی نیز به وقوع خواهند پیوست.
شش جنبه از مدیریت پروژه که متحوّل خواهند شد
ما پیشرفتهای فناورانهی پیشِ رو را فرصتی میبینیم که هیچگاه وجود نداشتهاند. آن سازمانها و رهبران پروژهای که بیشترین آمادگی را برای این لحظهی تحوّلآفرین دارند، بیشترین پاداش را از آن کسب خواهند کرد. تقریباً تمام جنبههای مدیریت پروژه، از برنامهریزی گرفته تا فرایندها و افراد درگیر در پروژهها، تحت تأثیر قرار خواهند گرفت. بیایید نگاهی به این شش حوزهی کلیدی بیندازیم.
۱- انتخاب و اولویتبندی بهتر پروژهها
انتخاب و اولویتبندی، هر دو مهارتهایی از نوع پیشبینی هستند: کدام پروژهها بیشترین ارزش را برای سازمان خواهند آفرید؟ چنانچه دادههای صحیح در دسترس باشند، یادگیری ماشینی قادر است الگوهایی را تشخیص دهد که با روشهای دیگر قابل تشخیص نیستند و لذا میتواند بسیار فراتر از دقّت انسانها در انجام پیشبینیها برود. اولویتبندی مبتنی بر یادگیری ماشینی به زودی منجر به حصول مزیّتهای زیر خواهد شد:
– شناسایی سریعتر آن دسته از پروژههای آماده به کار که پایه و اساس اولیهی یک پروژه را در اختیار دارند
– انتخاب پروژههایی که شانس موفقیت بیشتری دارند و بالاترین آورده را برای سازمان خواهند داشت
– تعادل بهتر در سبد پروژهها و ارائهی نمای اجمالی از وضعیت مخاطرات در سازمان
– حذف سوگیریهای انسانی از فرایندهای تصمیمگیری
۲- پشتیبانی از دفاتر مدیریت پروژه
شرکتهای نوپا در زمینهی تجزیهوتحلیل و خودکارسازی دادهها اکنون به سازمانها این یاری را میرسانند تا نقش دفاتر مدیریت پروژه (PMO) را ساده و بهینه سازند. معروفترین نمونهی آن، استفادهی رئیسجمهور فرانسه امانوئل ماکرون از جدیدترین فناوری برای بهروز نگاهداشتن اطلاعات خود در خصوص تمامی پروژههای بخش عمومی فرانسه است. این ابزارهای هوشمند جدید، نحوهی عملیات و عملکرد دفاتر مدیریت پروژه را به طور اساسی در موارد زیر تغییر خواهند داد:
– نظارت بهتر بر پیشرفت پروژهها
– قابلیت پیشبینی مشکلات احتمالی و رسیدگی خودکار به برخی از موارد که سادهتر هستند
– تهیه و توزیع خودکار گزارشهای پروژه و جمعآوری بازخوردها از مخاطبین
– پیچیدگی بیشتر در انتخاب بهترین روش مدیریت پروژه برای هر پروژهی خاص
– نظارت بر وضعیت انطباق پروژهها با فرایندها و سیاستها
– خودکارسازی کارکردهای پشتیبان، با بهرهگیری از دستیارهای مجازی پروژه، همچون بهروزرسانی وضعیتها، ارزیابی مخاطرات و تجزیهوتحلیل ذینفعان
۳- تسریع و بهبود در تعریف، برنامهریزی و گزارشدهی پروژهها
یکی از حوزههای بیشتر توسعهیافته برای خودکارسازی مدیریت پروژه، موضوع مدیریت مخاطرات است. برنامههای کاربردی جدید از کلاندادهها و یادگیری ماشینی برای کمک به رهبران و مدیران پروژه برای پیشبینی مخاطراتی که در غیر این صورت ممکن بود مورد توجه قرار نگیرند، استفاده میکنند. این ابزارها میتوانند اقداماتی برای تخفیف مخاطرات (Risk Mitigation) پیشنهاد دهند و به زودی خواهند توانست برنامههای مدیریت مخاطرات را به طور خودکار به نحوی که موجب جلوگیری از بروز انواع خاصی از مخاطرات شوند، تنظیم نمایند.
رویکردهای مشابه دیگری نیز به زودی تعریف، برنامهریزی و گزارشدهی در پروژهها را تسهیل خواهند کرد. در حال حاضر انجام این تکالیف زمانبر، تکراری و بیشتر آنها دستی هستند. یادگیری ماشینی، پردازش زبان طبیعی و خروجی متن ساده (Rich text) منجر به دستاوردهای زیر خواهند شد:
– بهبود مدیریت محدوده در پروژهها با خودکارسازی جمعآوری و تجزیهوتحلیل زمانبر دانستههای کاربران. این ابزارها مشکلات احتمالیای مانند ابهامات، تکرارها، جا افتادنها، ناهماهنگیها و پیچیدگیها را آشکار میسازند.
– ابزارهایی برای تسهیل فرایندهای زمانبندی و پیشنویسی برنامههای تفصیلی و مدیریت تقاضا برای تخصیص منابع در پروژهها
– گزارشدهی خودکار به نحوی که نه تنها گزارشات با کار کمتری تولید خواهند شد، بلکه اطلاعات موجود در گزارشهای امروزی، که اغلب چندین هفته قدیمی هستند، با دادههای بیدرنگ جایگزین میشوند. همچنین این ابزارها عمیقتر از آنچه که اکنون امکانش وجود داشته باشد در دادهها کنکاش خواهند کرد و وضعیت پروژهها، مزایای بهدستآمده، لغزشهای احتمالی و احساسات درونتیمی را به روشی واضح و عینی نشان میدهند.
۴- دستیاران مجازی پروژه
در عمل چَتجیپیتی (ChatGPT) یک شبه درک جهان را نسبت به آنکه چگونه هوش مصنوعی قادر است مجموعهای از دادهها را تجزیهوتحلیل نموده و بینشهای جدید و آنی را در قالب خروجی متن ساده تولید کند، تغییر داد. ابزارهایی از این دست در مدیریت پروژهها، به «رباتها» یا «دستیاران مجازی» قدرت میبخشند. اوراکل (Oracle) اخیراً دستیار دیجیتالی مدیریت پروژهی جدیدی را معرفی کردهاست که امکان بهروزرسانی آنی وضعیتها در پروژه را ارائه میدهد و به کاربران کمک میکند تا زمان و پیشرفت کارها را از طریق متن، صدا یا گَپ (Chat) بهروزرسانی نمایند.
این دستیار دیجیتالی از دادههای قبلی واردشده برای ثبت زمانها، دادههای برنامهریزی پروژه و زمینهی کلی پروژه یاد میگیرد تا تعاملات را تنظیم کرده و اطلاعات حیاتی پروژه را بهطور هوشمندانه ثبت نماید. پیموتو (PMOtto) یک دستیار مجازی پروژه با قابلیت یادگیری ماشینی است که در حال حاضر نیز استفاده میشود. یک کاربر میتواند از پیموتو بخواهد: «برنامهی جان (John) را برای نقاشی دیوارها در هفته آینده تنظیم کن و او را تمام وقت به این کار تخصیص بده». دستیار ممکن است پاسخ دهد، «بر اساس وظایف مشابه قبلی که به جان اختصاص داده شدهاند، به نظر میرسد که او برای انجام کار به دو هفته زمان نیاز داشته باشد و نه یک هفته آنطور که شما درخواست کردید. آیا باید آن را تنظیم کنم؟»
۵- سامانهها و نرمافزارهای پیشرفته برای آزمون نتایج
آزمون نتایج تحویلدادنی یکی دیگر از وظایف ضروری در اکثر پروژهها هستند و مدیران پروژه مجبور هستند این آزمونها را با سرعت و تداوم انجام دهند. امروزه به ندرت میتوان پروژهای بزرگ را یافت که فاقد چندین سامانه و انواع نرمافزارهایی باشد که باید قبل از تحویل پروژه آزمایش شوند. به زودی و بهطور گسترده، سامانههای پیشرفتهی آزمون که اکنون فقط برای پروژههای بزرگ قابل استفاده هستند، بیشتر در دسترس خواهند بود.
خط ریلی الیزابت که بخشی از پروژهی کراسریل (Crossrail) در بریتانیا است، یک راهآهن پیچیده با ایستگاههای جدید، زیرساختهای جدید، مسیرهای جدید و قطارهای جدید است. بنابراین، مهم است که تکتک عناصر پروژه از یک فرایند آزمون و راهاندازی دقیق برای اطمینان از ایمنی و قابلیت اطمینانپذیری در آنها، عبور داده شوند. این عملیات به ترکیبی از سختافزارها و نرمافزارهایی که قبلاً وجود نداشتند نیاز داشت و پس از چالشهای اولیه، تیم پروژه «تأسیسات یکپارچهسازی کراسریل» را توسعه داد. این تأسیسات آزمون کاملاً خودکار که خارج از سایت پروژه قرار دارد، اکنون ثابت کردهاست که چه ارزش غیرقابل اندازهگیریای در افزایش کارایی، بهصرفهسازی و انعطافپذیری سامانهها داشتهاست. مهندس این سامانه، اَلِساندرا شول-اِستِرنبرگ (Alessandra Scholl-Sternberg) برخی از ویژگیهای آن را اینگونه شرح میدهد: «کتابخانهی گستردهای از خودکارسازی سامانهها نوشته شدهاست که امکان دستیابی به تنظیمات پیچیده، انجام دقیق بررسیهای سلامت، انجام آزمونهای استقامتی در دورههای طولانی و اجرای آزمونهایی با ماهیت تکراری را فراهم میسازند.» در این مرکز ، امکان انجام ممیزیهای دقیق بهصورت ۲۴×۷ بدون نگرانی از مخاطرات و تأثیر ناشی از سوگیری کاربران سامانه وجود دارد.
به زودی، راهحلهای پیشرفته و خودکار برای انجام آزمون سامانهها در پروژههای نرمافزاری، امکان تشخیص زودهنگام عیوب و اجرای فرایندهای خوداصلاحگر را فراهم میسازند. این امر زمان صرفشده برای فعالیتهای دستوپاگیر در آزمونها را به میزان قابل توجهی کاهش میدهد، تعداد دوبارهکاریها را کم میکند و در نهایت راهحلهایی با کاربری آسان و بدون اشکال ارائه میدهد.
۶- یک نقش جدید برای مدیران پروژه
ممکن است خودکارسازیِ بخش قابل توجهی از وظایف فعلی مدیران پروژه، برای بسیاری از آنها ترسناک باشد، اما افراد موفّق یاد خواهند گرفت که از این ابزارها به نفع خود استفاده نمایند. مدیران پروژه حذف نخواهند شد، بلکه مجبور خواهند شد این تغییرات را بپذیرند و از فناوریهای جدید بهره ببرند. ما در حال حاضر تیمهای چندتخصّصی در پروژهها را با ترکیبی متشکّل از افراد مختلف میشناسیم، اما ممکن است به زودی آنها را به شکل گروههایی متشکّل از انسانها و رباتها در کنار یکدیگر ببینیم.
در آینده مدیران پروژه با دور شدن از کارهای اداری، باید مهارتهای قوی نرم، قابلیتهای رهبری، تفکّر راهبردی و هوش تجاری را در خود پرورش دهند. آنها باید بر حصول منافع مورد انتظار و همسویی آن منافع با اهداف راهبردی سازمان تمرکز نمایند. همچنین آنها به یک درک خوب از این فناوریها نیاز خواهند داشت. برخی از سازمانها در حال حاضر نیز هوش مصنوعی را در برنامههای آموزشی و صدور گواهینامههای مدیریت پروژهی خود وارد کردهاند؛ دانشگاه نورثایسترن (Northeastern University) هوش مصنوعی را در برنامههای آموزش خود گنجانده است و به مدیران پروژه آموزش میدهد که چگونه از هوش مصنوعی برای خودکارسازی و بهبود مجموعهی دادهها و بهینهسازی ارزش سرمایهگذاری در پروژهها استفاده نمایند.
دادهها و انسانها به آینده واقعیت میبخشند
چگونه میتوانید اطمینان داشتهباشید، زمانی که این ابزارها برای استفاده در سازمانها به آمادگی کافی برسند، سازمان شما نیز آمادگی لازم برای استفاده از آنها را خواهد داشت؟ هر فرایند پذیرش فناوریهای هوش مصنوعی در سازمان با آمادهسازی دادهها آغاز میشود، اما شما نباید نسبت به آمادهسازی افراد تیم خود نیز کوتاهی نمایید.
آموزش الگوریتمهای هوش مصنوعی برای مدیریت پروژهها به مقادیر زیادی دادههای مرتبط با پروژه احتیاج دارد. شاید سازمان شما مجموعهای از دادههای تاریخی پروژهها را حفظ کردهباشد، اما به احتمال زیاد این دادهها در هزاران سند در قالبهای مختلف پراکنده هستند و در سامانههای متعدّد ذخیرهسازی شدهاند. این اطلاعات ممکن است قدیمی باشند، ممکن است از طبقهبندیهای مختلف استفاده کردهباشند، یا حاوی دادههای بیربط و یا شکافهایی در دادههای اصلی باشند. تقریباً 8۰ درصد از زمان صرفشده برای آمادهسازی الگوریتمهای یادگیری ماشینی بر روی جمعآوری و پاکسازی دادهها تمرکز دارد که طی آن، دادههای خام و بدون ساختار به دادههای ساختاریافتهای تبدیل میشوند که قادر هستند یک مدل یادگیری ماشینی را آموزش دهند.
هرگز تحوّل هوش مصنوعی در سازمان شما بدون وجود دادههای در دسترس و دادههای مدیریتشدهی مناسب اتفاق نخواهد افتاد؛ اما اگر خود و تیمتان را برای تغییر آماده نکنید نیز هیچ تحوّلی در هوش مصنوعی شکوفا نخواهد شد.
این نسل جدید از ابزارها نه تنها فناوریهایی را که ما در مدیریت پروژهها استفاده میکنیم تغییر میدهند، بلکه کار ما را نیز به کلی در پروژهها متحوّل خواهند کرد. مدیران پروژه باید برای مربّیگری و آموزش تیمهای خود جهت انطباق با این انتقال آماده باشند. آنها باید تمرکز خود را بر روی تعاملات انسانی افزایش دهند و در عین حال کاستیهای مهارتی فناورانه را در افراد خود شناسایی کرده و برای رفع آنها تلاش نمایند. مدیران پروژه باید علاوه بر تمرکز بر نتایج تحویلدادنی در پروژهها، بر ایجاد تیمهایی با عملکرد بالا نیز تمرکز نمایند، به گونهای که اعضای تیم آنچه را که به آنها اجازه میدهد بهترین عملکرد را از خود نشان دهند، در اختیار دارند.
اگر به طور جدی در حال بررسی استفاده از هوش مصنوعی در پروژهها و شیوههای مدیریت پروژهی خود هستید، سؤالات زیر به شما کمک میکنند تصمیم خود را بهتر ارزیابی نمایید؛
– آیا این آمادگی را دارید تا برای تهیه فهرست دقیقی از تمام پروژههای در اختیار خود، از جمله آخرین وضعیت بهروزشده در آنها، زمان صرف نمایید؟
– آیا قادر هستید بخشی از منابع خود را چندین ماه برای جمعآوری، پاکسازی و ساختارمندسازی دادههای موجود در پروژههای خود اختصاص دهید؟
– آیا تصمیم خود را گرفتهاید که عادات قدیمی مدیریت پروژهی خود را از جمله گزارشهای پیشرفت ماهانه کنار بگذارید؟
– آیا آمادهی سرمایهگذاری در آموزش مجموعهی مدیریت پروژهی خود برای استفاده از این فناوریهای جدید هستید؟
– آیا آنها نیز تمایل دارند از مناطق سنّتی آسایش خود خارج شوند و نحوهی مدیریت پروژههای خود را به طور اساسی تغییر دهند؟
– آیا سازمان شما آمادهی پذیرش و بهکارگیری یک فناوری جدید و واگذاری کنترل تصمیمات به مراتب مهمتر به آن است؟
– آیا حاضر هستید اجازه دهید که این فناوری مرتکب اشتباه نیز بشود تا یاد بگیرد که برای سازمان شما چگونه عملکرد بهتری داشته باشد؟
– آیا حامی اجرایی در این پروژه، توانایی و اعتبار لازم در سازمان شما را دارد تا رهبری این تحوّل را در دست بگیرد؟
– آیا رهبران ارشد مایل هستند چندین ماه تا یک سال، منتظر بمانند تا مزایای خودکارسازی را مشاهده نمایند؟
اگر پاسخ به همهی این سوالات مثبت است، پس شما آمادهی شروع این تحوّل پیشگام هستید. اگر یک یا چند پاسخ «نه» دارید، باید قبل از حرکت آنها را به سمت «بله» سوق دهید.
•••
همانطور که دیدیم، استفاده از هوش مصنوعی در مدیریت پروژهها مزایای قابل توجهی را به همراه خواهد داشت، نه تنها در خودکارسازی وظایف اداری و کمارزش، بلکه مهمتر از آن، هوش مصنوعی و سایر فناوریهای مخرّب در جعبهی ابزار شما از جمله به سازمان شما کمک میکنند رهبران و مدیران پروژه، پروژهها را با موفقیت بیشتری انتخاب، تعریف و اجرا نمایند.
مدیر عامل داستان ما زمانی در موقعیتی قرار داشت که شما امروز در آن قرار گرفتهاید. ما شما را تشویق میکنیم که از هماکنون اولین گامها را به سمت این چشمانداز مثبت از آیندهی مدیریت پروژه بردارید.
دربارهی نگارندگان
آنتونیو نیتو رودریگز (Antonio Nieto-Rodriguez) نویسندهی کتاب راهنمای مدیریت پروژه هاروارد بیزینس ریویو (Harvard Business Review) ، مقالهی زمان اقتصاد پروژه رسیده است HBR (The Project Economy Has Arrived) و پنج کتاب دیگر است. تحقیقات و تاثیرات جهانی آثار او بر مدیریت مدرن توسط تینکرز۵۰ (Thinkers50) به رسمیت شناخته شدهاند. آنتونیو پیشرو در آموزش و مشاورهی هنر و علم پیادهسازی راهبردها و مدیریت مدرن پروژهها به مدیران اجرایی، استاد مدعو در هفت مدرسهی تجاری پیشرو است. او بنیانگذار پراجکتساَندکو (Projects&Co) و مؤسّسهی پیادهسازی راهبردها (Strategy Implementation Institute) است. میتوانید آنتونیو را از طریق تارنمای او، خبرنامهی لینکدین او با عنوان پروژهها را با موفقیت رهبری کنید (Lead Projects Successfully) و دورهی آنلاین او بازاختراع مدیریت پروژه برای مدیران غیر پروژهای (Project Management Reinvented for Non–Project Managers) دنبال نمایید.
دکتر ریکاردو ویانا وارگاس (Ricardo Viana Vargas)، بنیانگذار و مدیر عامل ماکروسُلوشنز (Macrosolutions)، یک شرکت مشاورهی بینالمللی در حوزهی انرژی، زیرساخت، فناوری اطلاعات، نفت و امور مالی است. او بیش از ۲۰ میلیارد دلار پروژههای بینالمللی را در 25 سال گذشته مدیریت کرده است. ریکاردو، برایتلاین اینشیتیو (Brightline Initiative) را از سال ۲۰۱۶تا ۲۰۲۰ایجاد و رهبری کرد و مدیر زیرساختها و تیم مدیریت پروژهها در سازمان ملل متحد بود و بیش از 1000 پروژه بشردوستانه و توسعهای را رهبری کرد. او ۱۶ کتاب در این زمینه نوشتهاست و میزبان «پادکست ۵ دقیقهای» است که تا کنون به آمار ۱۲ میلیون بازدید رسیدهاست.
منتشر شده در وبسایت Harvard Business Review
برگردان توسط حامد معینفر
در شرکت مهندسین فناور پندار آریا – پنداریا

 وبسایت منتشر کننده: Forbes
وبسایت منتشر کننده: Forbes
 تیموتی لیو (Timothy Liu) مدیر ارشد فناوری (CTO) و یکی از بنیانگذاران شبکههای هیلاستون (Hillstone Networks) است . سوابق کامل اجرایی تیم لیو را در این آدرس بخوانید.
تیموتی لیو (Timothy Liu) مدیر ارشد فناوری (CTO) و یکی از بنیانگذاران شبکههای هیلاستون (Hillstone Networks) است . سوابق کامل اجرایی تیم لیو را در این آدرس بخوانید.



 وبسایت منتشر کننده:
وبسایت منتشر کننده: 
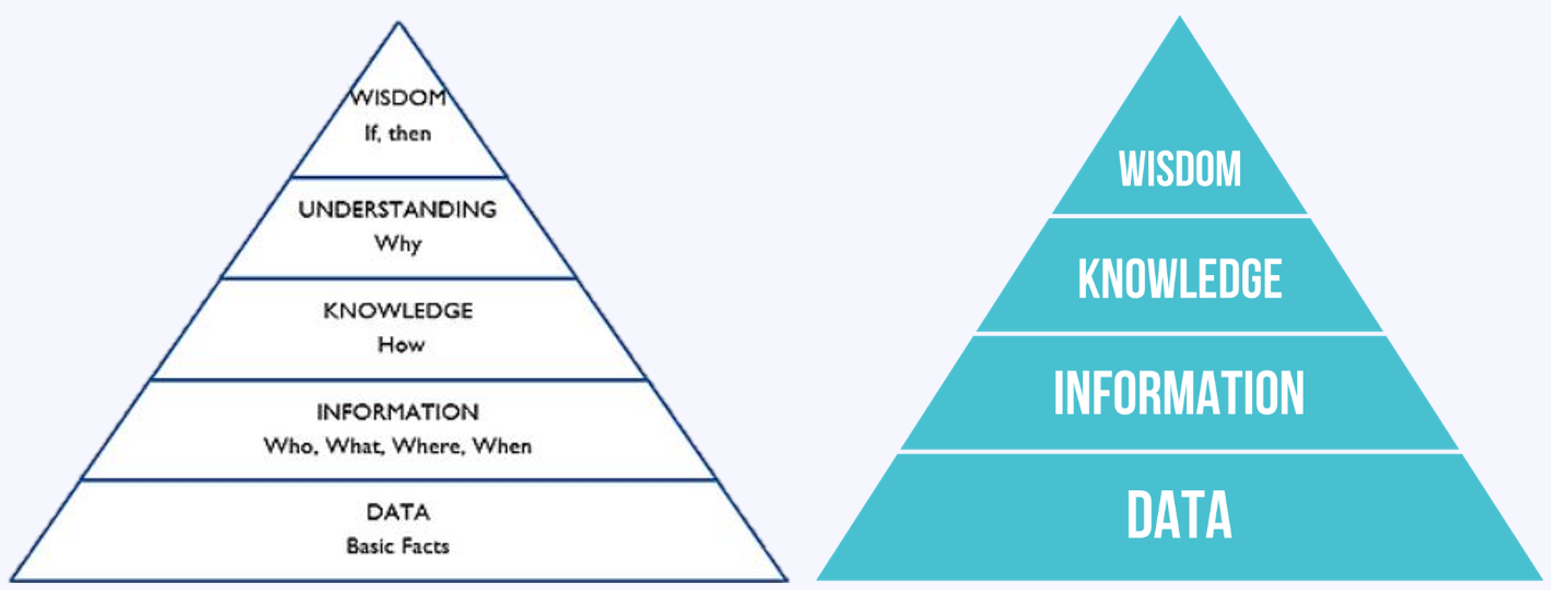 هرم دانش DIKW (داده-اطلاعات-دانش-خِرَد) – ویکیپدیا هرم دانش DIKUW (داده-اطلاعات-دانش-درک-خِرَد) – فوربس
هرم دانش DIKW (داده-اطلاعات-دانش-خِرَد) – ویکیپدیا هرم دانش DIKUW (داده-اطلاعات-دانش-درک-خِرَد) – فوربس
