آیا شما نیز در پروژههای هوش مصنوعی خود مرتکب این اشتباهات مرگبار میشوید؟
عنوان اصلی مقاله: ?Are You Making These Deadly Mistakes With Your AI Projects
تاریخ انتشار و نویسنده: By Kathleen Walch – Aug 20, 2022
 وبسایت منتشر کننده: Forbes
وبسایت منتشر کننده: Forbes
لینک اصلی مقاله

از آنجا که در قلب هوش مصنوعی (AI) دادهها قرار گرفتهاند، جای تعجب نیست که سامانههای هوش مصنوعی (AI) و یادگیری ماشینی (ML) برای «یادگیری»، نیازمند دادههای با کیفیت و با مقدار کافی باشند. به طور کلّی، به حجم زیادی از دادههای با کیفیت خوب، بهویژه برای رویکردهای «یادگیری با نظارت (Supervised learning)» نیاز است تا بتوان سامانهی AI یا ML را به صورت صحیح آموزش داد. ممکن است مقدار دقیق دادهای که مورد نیاز است، بسته به الگوی هوش مصنوعی که پیادهسازی میکنید، الگوریتمی که استفاده میکنید و عوامل دیگری از جمله دادههای داخلی در مقابل دادههای بیرونی، متفاوت باشد. به عنوان مثال، شبکههای عصبی (Neural networks) به دادههای زیادی برای آموزشیافتن نیاز دارند، در حالی که درختهای تصمیم (Decision trees) یا طبقهبندیکنندههای بِیز (Bayesian classifiers) به دادههای زیادی برای تولید نتایج با کیفیت بالا نیاز ندارند.
خُب، پس حالا ممکن است تصوّر کنید که هر چه حجم دادهها بیشتر بهتر، درست است؟ خیر، اشتباه فکر کردهاید. سازمانهایی با دادههای بسیار زیاد، حتی در حدّ اِگزابایت، اکنون متوجه شدهاند که بر خلاف انتظارشان حجم دادهی بیشتر راهحل مسألهی آنها نبوده است. در واقع، دادههای بیشتر یعنی مشکلات بیشتر. هر چه قدر دادههای بیشتری در اختیار داشته باشید، به همان میزان نیاز دارید تا دادههای بیشتری را تمیز و آمادهسازی کنید، دادههای بیشتری را برچسبگذاری و مدیریت کنید، دادههای بیشتری را ایمنسازی، محافظت و سوگیریزدایی کنید، و حتی موارد دیگر. به محض اینکه شما شروع به چند برابر کردن حجم دادهها نمایید، یک پروژهی کوچک به سرعت تبدیل به پروژهی بسیار بزرگ میشود. در واقع در بسیاری از اوقات، دادههای زیاد پروژهها را از بین میبرند.
به وضوح، حلقهی مفقوده از شناسایی یک مسألهی تجاری تا جمعکردن دادهها برای حل آن مسأله، این است که تعیین کنید به کدام دادهها و واقعاً به چه مقدار از آنها نیاز دارید. شما به اندازهی کافی داده نیاز دارید، امّا نه بیش از حدّ آن. چنانچه با برداشت از یک داستان کودکانه به آن «دادههای دختر موطلایی (Goldilocks)» اطلاق میکنند: نه خیلی زیاد، نه خیلی کم، بلکه به اندازه. متأسفانه در اغلب موارد، سازمانها بدون پرداختن به موضوع «درک اطلاعات»، وارد پروژههای هوش مصنوعی میشوند. پرسشهایی که لازم است سازمانها به آنها پاسخ دهند عبارتند از اینکه دادهها کجا قرار دارند، چه مقدار از آنها را در اختیار دارند، در چه شرایطی هستند، چه ویژگیهایی از آن دادهها بیشترین اهمیت را دارند؛ همچنین موضوعاتی چون استفاده از دادههای داخلی یا خارجی، چالشهای دسترسی به دادهها، نیاز به تقویت دادههای موجود، و سایر عوامل و سؤالات حیاتی. بدون پاسخ به این پرسشها، پروژههای هوش مصنوعی میتوانند به سرعت نابود شوند.
درک بهتر دادهها برای اینکه متوجه شوید به چه مقدار داده نیاز دارید، ابتدا باید درک کنید که دادهها چگونه و در کجای ساختار پروژههای هوش مصنوعی قرار میگیرند. یک روش بصری برای درک سطوح ارزش فزایندهای که از دادهها به دست میآوریم، «هرم دانش» (DIKUW و یا به قولی دیگر DIKW) است که نشان میدهد چگونه بنیادی از دادهها، به ایجاد ارزش بیشتر در لایههای «اطلاعات»، «دانش»، «درک» و «خِرَد» کمک میکند.
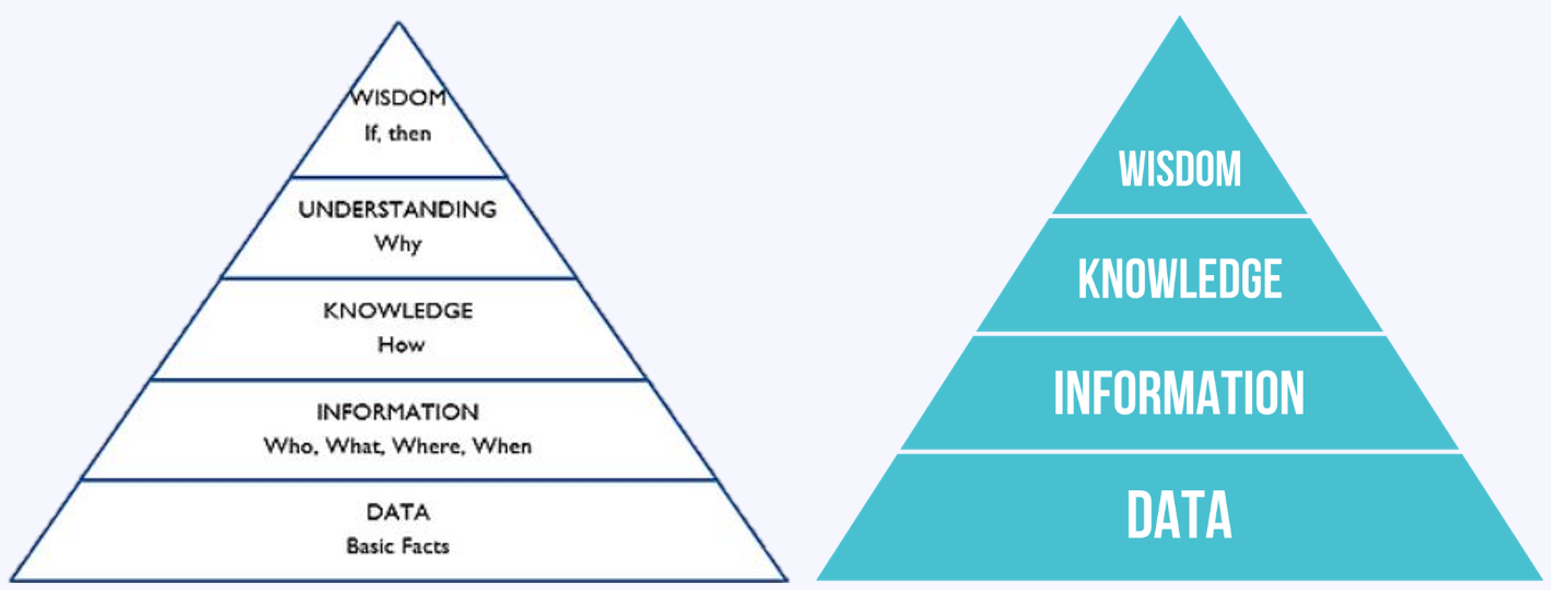 هرم دانش DIKW (داده-اطلاعات-دانش-خِرَد) – ویکیپدیا هرم دانش DIKUW (داده-اطلاعات-دانش-درک-خِرَد) – فوربس
هرم دانش DIKW (داده-اطلاعات-دانش-خِرَد) – ویکیپدیا هرم دانش DIKUW (داده-اطلاعات-دانش-درک-خِرَد) – فوربس
با یک بنیاد محکم از دادهها، میتوانید در لایهی بعدی یعنی اطلاعات، بینش مضاعفی به دست آورید که به شما کمک میکند به سؤالات ابتدایی در مورد آن دادهها پاسخ دهید. زمانی که یک سری ارتباطات اوّلیه بین دادهها ایجاد نمودید تا بینش اطلاعاتی به دست آورید، آنگاه میتوانید الگوهایی در آن اطلاعات بیابید که شما را قادر میسازد تا درک کنید که چگونه قطعات مختلف آن اطلاعات برای به دستآوردن بینش بیشتر به یکدیگر متصل شدهاند. با بنا نهادن بر روی لایهی دانش، سازمانها قادر هستند ارزش حتی بیشتری از درک اینکه چرا آن الگوها اتفاق میافتند به دست آورند و درک درستی از الگوهای زیربنایی ارائه دهند. در نهایت، لایهی خِرَد جایی است که میتوانید با ارائهی بینش در مورد علت و معلول تصمیمگیریهای اطلاعاتی، بیشترین ارزش را از اطلاعات در آن کسب نمایید.
این آخرین موجی که از هوش مصنوعی به راه افتادهاست، بیشتر بر روی لایهی دانش متمرکز است، چرا که هدف یادگیری ماشینی ارائهی بینش بر روی لایهی اطلاعات برای شناسایی الگوها میباشد. متأسفانه، یادگیری ماشینی در لایهی درک به محدودیتهای خود نزدیک میشود، زیرا یافتن الگوها برای انجام استدلال کافی نیست. ما یادگیری ماشینی داریم، نه اما «استدلال ماشینی» لازم برای درک اینکه چرا الگوها اتفاق میافتند. این محدودیت را میتوانید در عمل، زمانی که با یک «رُبات گفتگو» تعامل میکنید تجربه نمایید. در حالی که پردازشگرهای زبانهای طبیعی (NLP) که با یادگیری ماشینی توانمندسازی شدهاند در درک گفتار و هدف شما واقعاً خوب عمل میکنند، اما در درککردن و استدلالکردن با محدودیتهایی مواجه هستند. برای مثال، اگر از یک دستیار صوتی بپرسید که آیا باید فردا بارانی بپوشید، متوجه نمیشود که از آب و هوا سؤال کردهاید. این یک انسان است که باید این بینش را در اختیار ماشین قرار دهد، چرا که دستیار صوتی نمیداند باران واقعاً چیست.
جلوگیری از شکست با حفظ آگاهی نسبت به دادهها
تجربهی کلاندادهها (Big data) به ما آموخته است که چگونه با مقادیر زیادی از داده روبرو شویم. نه تنها اینکه چگونه آنها را ذخیره کنیم، بلکه چگونه تمام آن دادهها را پردازش، دستکاری و تجزیه و تحلیل کنیم. یادگیری ماشینی با توانایی کار با طیف گستردهای از انواع مختلف دادههای بدون ساختار، نیمه ساختاریافته و یا ساختاریافتهی جمعآوریشده توسط سازمانها، ارزش بیشتری را برای ما به همراه داشتهاست. اتفاقاً، این آخرین موج AI در حقیقت یک موج تحلیلی مبتنی بر دادههای بزرگ است.
اما دقیقاً به همین دلیل است که برخی از سازمانها با این شدت در هوش مصنوعی شکست میخورند. به جای آنکه پروژههای هوش مصنوعی خود را با یک دیدگاه دادهمحور اجرا کنند، آنها بر جنبههای عملکردی آن تمرکز میکنند. سازمانها برای در دست گرفتن مدیریت پروژههای هوش مصنوعی و اجتناب از اشتباهات مرگبار، نه تنها به درک بهتری از هوش مصنوعی و یادگیری ماشینی نیاز دارند، بلکه باید به «V»های کلانداده نیز توجه داشتهباشند. این که چقدر داده در اختیار دارید به تنهایی اهمیت ندارد، بلکه ماهیت آن دادهها نیز مهم است. برخی از آن «V»های کلانداده عبارتند از:
- حجم (Volume): آن مقدار و حجمی از کلاندادهها که در اختیار دارید.
- سرعت (Velocity): آن سرعتی که کلاندادههای شما در حال تغییر هستند. بهکار بستن موفقیتآمیز هوش مصنوعی به معنای بهکار بستن AI برای دادههای با سرعت بالا است.
- تنوّع (Variety): ممکن است دادهها در قالبهای مختلفی از جمله دادههای ساختاریافته مانند پایگاههای داده، دادههای نیمه ساختاریافته مانند صورتحسابهای فروش، و دادههای بدون ساختار مانند ایمیلها، فایلهای تصویری و ویدئویی قرار گرفته باشند. سامانههای هوش مصنوعی موفق قادر هستند با این سطح از تنوّع دادهها سر و کار داشته باشند.
- درستی (Veracity): این به کیفیت و دقت دادههای شما و میزان اعتمادی که شما به دادههایتان دارید، اشاره میکند. زباله تحویل دهید، زباله تحویل میگیرید؛ بهویژه در سامانههای هوش مصنوعی مبتنی بر داده. به این ترتیب، سامانههای هوش مصنوعی موفق باید قادر باشند با تنوّع بالایی از کیفیت دادهها سر و کار داشته باشند.
با دههها تجربه در مدیریت پروژههای کلانداده، سازمانهایی که در هوش مصنوعی موفق هستند، در درجهی اوّل در پروژههای کلانداده موفق بودهاند. آنهایی که در حال مشاهدهی نابودی پروژههای هوش مصنوعی خود هستند، کسانی هستند که به مسائل هوش مصنوعی خود با ذهنیت توسعهی برنامههای کاربردی پرداختهاند.
مقدار زیاد دادههای نادرست و کافینبودن دادههای صحیح، در حال نابودی پروژههای هوش مصنوعی هستند
در حالی که پروژههای هوش مصنوعی درست آغاز میشوند، فقدان دادههای لازم و فقدان درک و سپس فقدان حل مسائل واقعی، پروژههای هوش مصنوعی را با نابودی مواجه ساختهاست. سازمانها همچنان در حال پیشروی بدون داشتن درک واقعی از دادههای مورد نیاز خود و کیفیت آن دادهها هستند؛ این موضوع چالشهای واقعی ایجاد کردهاست.
یکی از دلایلی که سازمانها این اشتباهات را در خصوص دادههای خود مرتکب میشوند این است که برای انجام پروژههای هوش مصنوعی از هیچ رویکرد واقعی به غیر از روشهای چابک (Agile) یا توسعهی برنامههای کاربردی استفاده نمیکنند. با این حال، سازمانهای موفق دریافتهاند که بهرهگیری از رویکردهای دادهمحورِ متمرکز بر درک دادهها را بهعنوان یکی از اوّلین مراحل در رویکردهایشان در پروژه قرار دهند. روششناسی CRISP-DM (فرایند استاندارد بین صنایع برای دادهکاوی)، که بیش از دو دهه است که وجود دارد، درک دادهها را به عنوان اولین کاری که باید پس از تعیین نیازهای کسبوکار خود انجام دهید، مشخص میکند. با پایه قرار دادن روش CRISP-DM و افزودن روشهای چابک به آن، روششناسی مدیریت شناختی پروژهها برای هوش مصنوعی (CPMAI)، درک دادهها در فاز دوی پیادهسازی را الزامی میداند. سایر رویکردهای موفق نیز به درک اطلاعات در اوایل پروژه تأکید دارند، زیرا بالاخره هر چه که باشد، پروژههای هوش مصنوعی پروژههای مبتنی بر دادهها هستند. و شما چگونه قادر خواهید بود یک پروژهی موفق مبتنی بر دادهها را بنا بگذارید، بدون آنکه پروژهی خود را با درک صحیح از دادهها اجرا نموده باشید؟ این قطعاً یک اشتباه مرگبار است که باید از آن اجتناب نمایید.
 کاتلین والش یک شریک مدیریتی و تحلیلگر اصلی در شرکت تحقیق و مشاورهی متمرکز بر هوش مصنوعی کاگنلیتکا (Cognilytica)، میباشد که بر کاربرد و استفاده از هوش مصنوعی (AI) در دو بخش عمومی و خصوصی متمرکز است. او همچنین میزبان پادکست محبوب AI Today بوده که یک پادکست برتر مرتبط با هوش مصنوعی است و موارد مختلف استفاده از هوش مصنوعی را برای دو بخش عمومی و خصوصی برجسته کرده و همچنین با کارشناسان مهمان در مورد موضوعات مرتبط با هوش مصنوعی مصاحبه میکند.
کاتلین والش یک شریک مدیریتی و تحلیلگر اصلی در شرکت تحقیق و مشاورهی متمرکز بر هوش مصنوعی کاگنلیتکا (Cognilytica)، میباشد که بر کاربرد و استفاده از هوش مصنوعی (AI) در دو بخش عمومی و خصوصی متمرکز است. او همچنین میزبان پادکست محبوب AI Today بوده که یک پادکست برتر مرتبط با هوش مصنوعی است و موارد مختلف استفاده از هوش مصنوعی را برای دو بخش عمومی و خصوصی برجسته کرده و همچنین با کارشناسان مهمان در مورد موضوعات مرتبط با هوش مصنوعی مصاحبه میکند.
منتشر شده در وبسایت Forbes
برگردان توسط حامد معینفر
در شرکت مهندسین فناور پندار آریا – پنداریا










