
هدایت چشمانداز در حال تغییر در امنیت مراکز داده
عنوان اصلی مقاله: Navigating The Changing Landscape In Data Center Security
تاریخ انتشار و نویسنده: by Tim Liu, Jun 28, 2023
 وبسایت منتشر کننده: Forbes
وبسایت منتشر کننده: Forbes
لینک اصلی مقاله

گِتی (Getty)
این گونه به نظر میرسد که نرخ نوآوریها در فناوری – و بدافزارها – سریعتر از هر زمان دیگر در حال رشد است. مدیران عامل (CEOs)، مدیران ارشد مالی (CFOs)، مدیران ارشد امنیت (CSOs) و سایر کسانی که مسؤول حفاظت از دادهها – یعنی باارزشترین داراییهای یک شرکت – هستند، باید در رأس هرم پیشرفتهای کلیدی باقی بمانند تا قادر باشند با چشمانداز در حال تغییر حوزهی امنیت همگام شوند.
ما در حال مشاهدهی سه روند کلیدی در این حوزه هستیم که تلاشها برای برقراری امنیت دسترسی در مراکز داده را در زمان حال و آینده شکل خواهند داد: ظهور هوش مصنوعی (AI) و یادگیری ماشین (ML)، پذیرش فزایندهی اصول اعتماد صفر (Zero-trust principles) و نیاز به امنیتی که بتواند محیطهای چنداَبری (Multi-cloud environments) را در بر بگیرد.
بهرهگیری از هوش مصنوعی و یادگیری ماشینی برای افزایش امنیت
هوش مصنوعی و یادگیری ماشینی برای سالهای متوالی در صنایع و سناریوهای متعدد مورد استفاده قرار گرفتهاند، اما اخیراً با انتشار چَتجیپیتی (ChatGPT) و ابزارهای مصرفی مشابه دیگر، توانستهاند تخیّل عموم را به خود جلب نمایند. در حوزهی امنیت مرکز داده، هوش مصنوعی و یادگیری ماشینی به ویژه برای تقویت سازوکارهای دفاعی، شناسایی ناهنجاریها و شاخصهای خطر و پاسخدهی خودکار به تهدیدات نوظهور مناسب هستند.
به عنوان نمونه، اِیآی و اِماِل قادر هستند با سرعتی بالا مجموعهی دادههای جمعآوریشده از گزارشها (Logs) و جریانهای دیگر اطلاعاتی را برای شناسایی تهدیدات احتمالی، حملات یا سوءاستفاده از دادههای شرکت و همچنین پیشبینی خطرات و آسیبپذیریهای احتمالی تجزیه و تحلیل کنند. با استفاده از این شیوهها میتوان با خُرد کردن بسیار سریع حجم عظیمی از دادهها، به تیمهای امنیتی کمک کرد که با توجه به مشغولیتهای بیش از حد خود از بسیاری از کارهای دستی خستهکننده خلاص شوند.
علاوه بر این، آنها قادر هستند نرخ شناسایی کدهای مخرّب (Exploits) کوچکتر اما اغلب خطرناکتری مانند تهدیدات مستمر پیشرفته (APTs: Advanced persistent threats)، حملات روز صفر (Zero-day attacks) و تهدیدات داخلی را افزایش دهند. همچنین «جامعهی بینالملل امنیت صنعتی» یا اَسیس اینترنشنال (ASIS International) خاطرنشان میکند: «این امکان وجود دارد که از ابزارهای هوش مصنوعی و یادگیری ماشینی برای کمک به تشخیص تهدیدها قبل از آنکه به بتوانند به سامانهها آسیب برسانند و یا در جمعآوری دادههای جرمشناسی برای کمک به واکنش در برابر حوادث و بازیابی از آنها استفاده کرد.»
با این حال، مشابه آنچه در همتایان هوش مصنوعی در ردهی مصرفکننده دیده میشود، ممکن است هوش مصنوعی و یادگیری ماشینی در امنیت مرکز داده نیز منجر به نتایج مثبت کاذب (False positives) شوند و در معرض سوگیری (Bias) قرار بگیرند. با «آموزش» زیرسیستمهای هوش مصنوعی امنیتی (Security AI) در زمان برقراری تعاملات عادی ترافیکی در مرکز داده و نیز از طریق فنون دیگر، میتوان دقت و اثربخشی را بهبود بخشید و آنها را با محیط، متناسب ساخت.
هوش مصنوعی و/یا یادگیری ماشینی در انواع فناوریهای امنیت سایبری از جمله فایروالهای نسل بعدی (Next-gen firewalls) و مدیریت اطلاعات و رویدادهای امنیتی (SIEM) و همچنین نمونههای جدیدتر معرفیشده در سکّوهای حفاظت از بارهای کاری ابری (Cloud workload protection) تعبیه شدهاند.
کنترل کردن دسترسی: زِدتیاِناِی (ZTNA)
در حالی که هوش مصنوعی و یادگیری ماشینی اغلب برای تقویت امنیت «در داخل» مراکز داده استفاده میشوند، باید توجه داشت که کنترل اینکه «چه کسی» و «چه چیزی» ممکن است به منابع حیاتی دسترسی داشته باشد نیز حداقل به همان اندازه اهمیت دارد، اگر که حتی اهمیت آن بیشتر نباشد. در نتیجه، مدیران مراکز داده به طور فزایندهای در حال اتخاذ رویکرد دسترسی شبکه با اعتماد صفر یا زِدتیاِناِی (ZTNA) هستند که در آن با هر کاربر، دستگاه و یا تعامل، با دید بالقوه مخرّب رفتار میشود.
با زِدتیاِناِی، تمام تلاشها برای برقراری دسترسی به شبکه تنها پس از پایان عملیات کامل احراز هویت (Authentication) و تجویز دسترسی (Authorization) در سطح چندین عامل تأیید میشوند، و حتی همین دسترسی نیز فقط برای منابع مشخص بر اساس آگاهی زمینهای از آن درخواست و «اصول حداقل امتیاز» اعطاء میشود. این فرایند در طول نشست به طور مستمر ادامه پیدا میکند تا هرگونه تغییر در وضعیت امنیتی یا سایر شاخصهای تهدید را شناسایی نماید.
اصول اعتماد صفر در تضاد مستقیم با شبکههای خصوصی مجازی (VPN) هستند که معمولاً دسترسی را به تمام یک شبکه یا زیرشبکه (Subnet) باز میکنند. همچنین ویپیاِنها به گونهای طراحی شدهاند که فقط یک بار در شروع نشست هویت کاربران را احراز و مجوز صادر میکنند و اغلب از یک سامانهی ورود یکپارچه (SSO: Single Sign-On) برای اعطای دسترسی به طیف گستردهای از خدمات، برنامهها و دادهها استفاده میکنند.
«دسترسی شبکه با اعتماد صفر» با فلسفهای که برای خود دارد میتواند سطح در معرض حمله را کاهش دهد و حتی از حرکات عرضی تهدیدات در مرکز داده جلوگیری نماید؛ مشخصاً «شبکههای رباتهای آلوده» یا باتنتها (Botnets)، باجافزارها (Ransomwares) و تهدیدهای مشابه دیگر. همچنین قادر است میدان دید را در کل محیطهای شبکهی فیزیکی و ابری برای پاسخ سریعتر به تهدیدات و همچنین ارائهی مدیریت یکپارچه و مقیاسپذیری آسانتر گسترش دهد.
با این حال، اتخاذ رویکرد زِدتیاِناِی (ZTNA) میتواند نسبتاً گران باشد و پیکربندی و مدیریت آن نیز اغلب پیچیده است. علاوه بر این، بر محیط پیرامونی تمرکز دارد و معمولاً قادر نیست حملات یا ناهنجاریها را تشخیص دهد. بنابراین همچنان فناوریهای امنیتی مضاعفی همانند آنچه در بالا ذکر شدند، مورد نیاز خواهند بود.
ایمنسازی محیطهای چنداَبری
سومین روند کلیدی که در امنیت مراکز داده شاهد آن هستیم، گسترش استقرارهای چنداَبری و چالشهای حفاظت از دادهها و برنامهها در این سکّوهای متنوع است. مدیران مراکز داده به طور فزایندهای در حال اتخاذ راهبردهای چنداَبری در جهت افزایش تابآوری و اطمینانپذیری دادهها و خدمات، اجتناب از وابستگی مالکانه به فروشندگان، کاهش هزینهها و سایر ملاحظات هستند.
با این حال، مراکز دادهای که یک محیط چنداَبری را به کار میگیرند، سطح در معرض حملهی بسیار وسیعتری را نیز در دسترس قرار میدهند که منجر به پیچیدگی در عملیات شبکه و امنیت سایبری میشود. بنابراین، حفظ میدان دید و کنترل گسترده به یک ملاحظهی کلیدی در طراحی و مدیریت این معماریها تبدیل میشود.
برای مثال، سیاستها و کنترلهای امنیتی باید در سطح تمام ابرها پیادهسازی شوند و باید به طور منظم نگهداری و بهروز نگاه داشته شوند. اغلب، یک سکّوی متمرکز که به گرهها یا نودهای (Nodes) محلّی وصل است، قادر است میدان دید و قابلیت پایش و مدیریت مرکزی وضعیت امنیت سایبری را در سراسر محیط چنداَبری فراهم کند. همچنین ممکن است این خدمات یا دستگاهها در جهت سادهسازی عملیات، امکاناتی برای خودکارسازی و هماهنگسازی ارائه دهند و در عین حال خطر وقوع خطاهای انسانی را به حداقل برسانند.
علاوه بر این، رمزنگاری دادهها – چه در حالت ذخیره و چه در حالت انتقال – میتواند وضعیت امنیتی را بیشتر تقویت کند و زِدتیاِناِی قادر است محیط پیرامونی را بدون توجه به موقعیت فیزیکی آن، امن سازد.
خلاصه
همچنان که فناوریهای امنیتی مراکز داده و چشمانداز تهدیدات تکامل مییابند، این بسیار حیاتی است که با چالشهای نوظهور سازگار شویم. در حال حاضر این سه روند کلیدی در صدر توجه بسیاری از مدیران ارشد امنیت و سایرینی که مسؤول امنیت مراکز داده و دادههای حساس موجود در آنها هستند، قرار گرفتهاند. این و سایر پیشرفتها میتوانند تابآوری در برابر تهدیدات پیچیده و همچنین دسترسیهای غیرمجاز یا سوءاستفاده از دادهها را بهبود بخشند.
مدیران ردهی ارشد (C-suite) با آگاهماندن از این روندها و سایر روندهای امنیتی، قادر هستند به تیمهای فناوری خود در اجرای راهبردهای قوی امنیتی که با اهداف کسبوکار همسو هستند، کمک کنند.
 تیموتی لیو (Timothy Liu) مدیر ارشد فناوری (CTO) و یکی از بنیانگذاران شبکههای هیلاستون (Hillstone Networks) است . سوابق کامل اجرایی تیم لیو را در این آدرس بخوانید.
تیموتی لیو (Timothy Liu) مدیر ارشد فناوری (CTO) و یکی از بنیانگذاران شبکههای هیلاستون (Hillstone Networks) است . سوابق کامل اجرایی تیم لیو را در این آدرس بخوانید.
منتشر شده در وبسایت فوربس Forbes
توسط تیم لیو (Tim Liu)، ۲۸ ژوئن ۲۰۲۳
برگردان توسط حامد معینفر
در شرکت مهندسین فناور پندار آریا – پنداریا

 وبسایت منتشر کننده:
وبسایت منتشر کننده: 

 وبسایت منتشر کننده:
وبسایت منتشر کننده: 
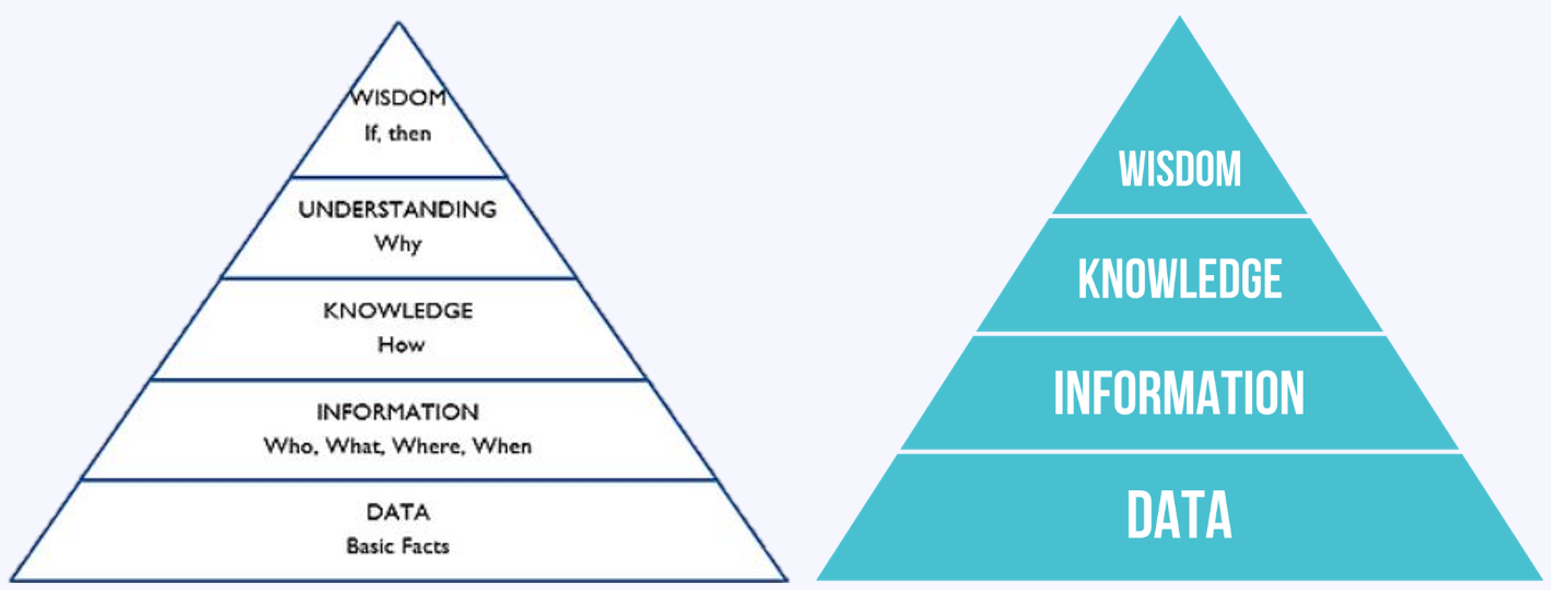 هرم دانش DIKW (داده-اطلاعات-دانش-خِرَد) – ویکیپدیا هرم دانش DIKUW (داده-اطلاعات-دانش-درک-خِرَد) – فوربس
هرم دانش DIKW (داده-اطلاعات-دانش-خِرَد) – ویکیپدیا هرم دانش DIKUW (داده-اطلاعات-دانش-درک-خِرَد) – فوربس
